Statistisch zand in de ogen strooien
Donderdag 1 december 2016
Een gastbijdrage van Jeroen Hetzler
De modellen die het IPCC hanteert waarmee dit VN-werktuig van o.a. Maurice Strong het mondiale politieke en economische beleid in de door de VN en de EU voorgestane anti kapitalistische sociaal-democratische richting wenst te sturen, mogen wel eens aan nadere beschouwing onderworpen worden. Laten we bijvoorbeeld kijken hoe de uitspraak van het IPCC in AR5 over de 95% betrouwbaarheid geïnterpreteerd moet worden dat de opwarming na 1950 voor zeker 50% door menselijk toedoen is veroorzaakt. Allereerst is niet duidelijk waar die 50% op is gebaseerd.
Het is in elk geval opmerkelijk, omdat het IPCC elke natuurlijke invloed uitsloot krachtens zijn mandaat. Is hier sprake van een paradigmaverschuiving?
Geen idee. Laten we nu kijken wat met die 95% betrouwbaarheid of betrouwbaarheidsinterval (BI) wordt bedoeld. De wetenschappelijke methode gaat als volgt. Eerst wordt een zogeheten nulhypothese geformuleerd bij bijvoorbeeld de test op het effect van een nieuw medicijn, het catastrofale effect van menselijke CO2-emissie op de mondiale temperatuur. U ziet in het woord ‘catastrofale’ al een verschil dat te denken moet geven omdat dit een a priori aanname lijkt waar elke definitie ontbreekt.
De nulhypothese stelt: er gaat geen significante verbetering uit van het nieuwe medicijn ten opzichte van de situatie zonder dit medicijn, tenzij door falsificatie ten gunste van de alternatieve hypothese: het nieuwe medicijn geeft een significante verbetering.
Dit antwoord blijkt na toetsing d.m.v. metingen. Hierover later meer. Wat betreft de CAGW-hypothese (Anthropogenic Global Warming; door de mens veroorzaakte catastrofale opwarming) wordt het drabbig.
Immers, Al Gore vertoonde zijn film An Incovenient Truth als een zekerheid, niet als een hypothese, en sloeg de toetsing van de nulhypothese over, maar deed deze a priori af als gefalsificeerd. Dit is iets wat je wel vaker uit de mond van alarmisten hoort, maar uiteindelijk blijkt het een teruggrijpen op het Voorzorgprincipe, niet op de wetenschappelijk methode van statistiek. Dit zand in de ogen strooien is waar de hoax van de ‘science is settled’ op vegeteert.
Dit wordt onderstreept door het commentaar van Trenberth 2011 met dit als antwoord van Curry.
De knullige vraag van Trenberth, namelijk bewijzen dat het niet zo is, doet denken aan de paranormale wereld waarin men met doden spreekt, door buitenaardse wezens is ontvoert, Ogilvie en Geller. Waar deze vraag schering en inslag is.
Nee, de bewijslast ligt echt bij degene die de nulhypothes in twijfel trekken. Er is sprake van de volgende nul-hypothese: klimaatveranderingen worden door natuurlijke krachten veroorzaakt. Deze staan tegenover de alternatieve hypothese, namelijk dat de huidige klimaatverandering van antropogene aard is. Logischerwijs ligt de bewijslast bij de alarmisten om aan te tonen dat de nul-hypothese niet in staat is om de empirische data te verklaren, en daarmee verworpen is ten gunste van de alternatieve hypothese.
Met andere woorden: alarmisten zullen met overtuigende meetgegevens moeten komen als bewijs voor de catastrofale antropogene klimaatverandering (CAGW). Zij moeten dit doen door gedetailleerde vergelijking van de data met de klimaatmodellen. Dit is natuurlijk uiterst moeilijk en praktisch onmogelijk, daar men de natuurlijke invloeden bij lange niet voldoende exact kan specificeren, omdat deze verre van doorgrond zijn.
Zo is de werking van wolkenvorming weinig verklaard. Hier kom ik later op terug. Bovendien is naast de formulering van een nulhypothese ook de formulering van een betrouwbaarheidsinterval nodig. Wat moet ik mij hierbij voorstellen? Stel, ik heb een zak met bruine bonen. Het gewicht per boon verschilt en wijkt af van het gemiddelde.
Hoe die spreiding rond het gemiddelde (μ) is, wordt uitgedrukt door het symbool σ (sigma). Stel dat ik door een ander bemestingsregiem denk dat mijn bonen gemiddeld zwaarder zijn. Dit moet ik toetsen. Vallen de meetresultaten binnen een bepaalde marge, dan levert de bemestingsmethode geen significant verschil op. Vallen ze erbuiten, dan wel. Die marge heet betrouwbaarheidsinterval. Bij toetsing wordt gewoonlijk uitgegaan van +/-2 sigma. Dus iets meer dan 95% betrouwbaarheidsinterval. Dit houdt in dat in 95 van de 100 gevallen de testresultaten in dit gebied vallen, tenzij… (figuur 1)
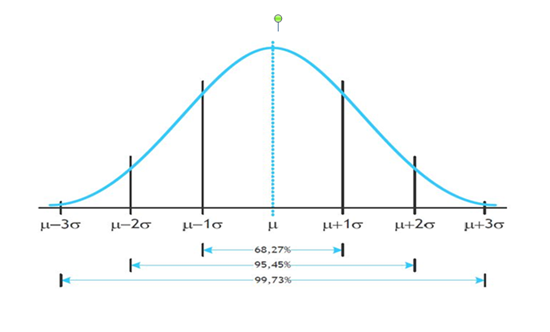 … resultaten er buiten vallen, want dan kan de nulhypothese verworpen worden. Dit heet falsificatie of weerlegging. Hier is een praktijkgeval:
… resultaten er buiten vallen, want dan kan de nulhypothese verworpen worden. Dit heet falsificatie of weerlegging. Hier is een praktijkgeval:
Het woord schatting impliceert dat het infectiepercentage met een zekere onnauwkeurigheid is gemeten. Het 95%-BI van een gemeten infectiepercentage geeft aan dat indien deze meting 100 maal wordt herhaald, de gemeten waarde 95 maal binnen het interval zal liggen dat wordt aangegeven. In de overige 5 keer zal het percentage buiten het interval liggen. Hoe kleiner dit interval, hoe preciezer de schatting van de werkelijke waarde is. Het interval wordt kleiner naarmate het gemeten infectiepercentage gebaseerd is op een groter aantal observaties: de meting wordt dan betrouwbaarder.
Om te bepalen of een verschil tussen infectiepercentages berust op toeval of op een werkelijk verschil is het mogelijk een statistische toets uit te voeren op de gegevens, bijvoorbeeld door het bepalen van een p-waarde of het vergelijken van de 95%-betrouwbaarheidsintervallen. Deze statistische toetsen gaan uit van de hypothese dat er geen verschil is tussen de verschillende observaties. Deze hypothese kan worden bevestigd of worden weerlegd. De p-waarde is de kans dat er een verschil gemeten is, terwijl er in werkelijkheid geen verschil is. Hoe kleiner de p-waarde, hoe groter de kans dat het gemeten verschil niet toevallig is. Als grenswaarde wordt bij de berekening van de p-waarde meestal 5% gekozen, overeenkomend met het 95% betrouwbaarheidsinterval. Het verschil is ‘significant’ als de gevonden p-waarde kleiner is dan de grenswaarde van 5% (p < 0,05) en ‘niet-significant’ als de p-waarde is groter dan 5%.
Aangezien het IPCC geen nulhypothese formuleert met bijbehorende p-waarde, is de voornoemde bewering in AR5 dat het extremely likely is als een zekerheid van 95%, misleidend en door handopsteken bepaald. Het was evenwel een meesterlijke PR- stunt waar de hele wereld met open ogen intrapte, omdat het lijkt op de zogenaamde betrouwbaarheidsintervallen uit de reguliere statistiek, maar in werkelijkheid berust op handopsteken iets wat aan alternatieve ‘geneeskunde’ als handlezen doet denken. Bovendien wekte het de onterechte indruk dat de wetenschap eruit is.
Een betrouwbaarheidsinterval is gebaseerd op betrouwbare meetgegevens, niet op een waaier van hypothetische modelresultaten. De modellen van het IPCC zijn immers alle hypotheses die elk afzonderlijk moeten worden getest, elk met een eigen betrouwbaarheidsinterval getoetst aan de meetresultaten. Zo lang dit niet is gebeurd (wat het geval is), kunnen de modellen geen representanten zijn van de werkelijkheid noch grond voor politiek beleid zijn. Thans is dit laatste slechts bepaald door handopsteken, omdat, nogmaals, de nulhypothese ontbreekt.
Hoe duidelijk wilt u het hebben? (figuur 2)
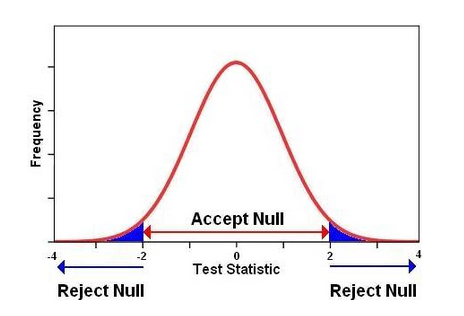 We zien weer het links en rechts 2 sigma-brede betrouwbaarheidsinterval. De gemeten temperaturen vallen na elke IPCC-AR buiten het dan geldende door het IPCC genoemde “betrouwbaarheidsgebied”, of wat moet doorgaan voor die waaier aan hypotheses (zie figuur 3). Dit was eerst 0,5 sigma, toen 0,75, 1 sigma en nu 2 sigma.
We zien weer het links en rechts 2 sigma-brede betrouwbaarheidsinterval. De gemeten temperaturen vallen na elke IPCC-AR buiten het dan geldende door het IPCC genoemde “betrouwbaarheidsgebied”, of wat moet doorgaan voor die waaier aan hypotheses (zie figuur 3). Dit was eerst 0,5 sigma, toen 0,75, 1 sigma en nu 2 sigma.
Er is derhalve na al die jaren nog steeds geen zicht op de waarde van de betrouwbaarheid bij gebrek aan een nulhypothese. Het enige dat je kunt zien, is dat er een nietszeggend gemiddelde voor alle modellen is gecreëerd dat als uitgangspunt dient voor het IPCC om de schijn van (statistische) wetenschappelijkheid te wekken. Dit leidt tot de volgende visualisatie van de uitspraken van het IPCC (figuur 3):
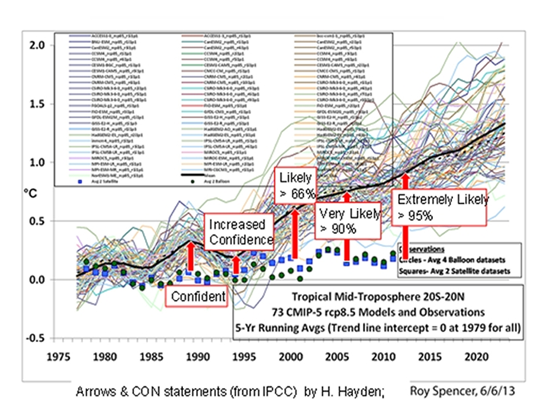 Het IPCC probeert dus, naarmate de meetresultaten steeds verder achterblijven bij dat nietszeggende gemiddelde van alle modellen, de lezer zand in de ogen te strooien door het imaginaire betrouwbaarheidsinterval telkens te verbreden om de meetresultaten binnen Accept Null van figuur 2 te houden, ofwel: de metingen tonen zogenaamd aan dat de modellen gelijkwaardig zijn aan de meetresultaten. De hele wereld inclusief zich kwaliteitskranten noemenden, zoals het NRC, trapte erin, maar van daadwerkelijke toetsing is nooit sprake geweest, omdat dit ook helemaal niet kan. Het is een lege bewering dus. Edoch, men kan er op wachten dat bij AR6 het virtually certain is (99%) zal gelden. Dit is uitstel van executie, want er komt een moment dat het IPCC zijn geloofwaardigheid in dezen verliest. Ik citeer:
Het IPCC probeert dus, naarmate de meetresultaten steeds verder achterblijven bij dat nietszeggende gemiddelde van alle modellen, de lezer zand in de ogen te strooien door het imaginaire betrouwbaarheidsinterval telkens te verbreden om de meetresultaten binnen Accept Null van figuur 2 te houden, ofwel: de metingen tonen zogenaamd aan dat de modellen gelijkwaardig zijn aan de meetresultaten. De hele wereld inclusief zich kwaliteitskranten noemenden, zoals het NRC, trapte erin, maar van daadwerkelijke toetsing is nooit sprake geweest, omdat dit ook helemaal niet kan. Het is een lege bewering dus. Edoch, men kan er op wachten dat bij AR6 het virtually certain is (99%) zal gelden. Dit is uitstel van executie, want er komt een moment dat het IPCC zijn geloofwaardigheid in dezen verliest. Ik citeer:
The IPCC has never ever defined a null hypothesis to build its case for human-caused global warming, even though all climate change is statistically based. That is flawed science. The null hypothesis above for climate change assumes that observed changes are caused by natural variability. If statistics prove it must be rejected, then the theory of human-caused global warming is strengthened. To go about testing the null hypothesis, compare any climate variable, like temperature rise – that overlaps times of natural variability with times thought human caused. IPCC AR5 says 1950 is the starting point where non-natural climate change effects begin to appear. Apply statistical analysis to data before and after 1950 and if the result is 95% or greater that the change is outside what natural variability allows then the null hypothesis – results are consistent with natural variability – must be rejected. That, of course, does not prove that human’s are the cause of climate change. It proves that climate change is outside the range of natural variability. In the world of science, though, that is considered very strong support for the theory of human-caused global climate change, though not proven absolutely. Since AGW theory attributes rising atmospheric CO2 levels to climate change, then a direct link beyond what cannot be explained by natural variability must be established. That is a standard the IPCC has yet to meet. (zie ook) Instead of using the standard scientific approach to support the theory of human-cause climate change, the IPCC takes the opposite and entirely false approach. From its very first report the IPCC has always assumed all climate change is human-caused and seeks out data and builds mathematical modeling to support it. It’s a tainted approach that assumes true the very thing you are out to prove. That is both unscientific and illogical.
Oftewel: het IPPC had het ‘antwoord’ al klaar en scharrelt er de argumenten bij. Statistisch een doodzonde. En het gaat veel verder, want over de toepassing van bovengenoemde gebruikelijke statistische methoden op de klimaatmodellen valt het een en ander te zeggen. Zo heb ik mij er over verbaasd wat de toegevoegde waarde is van het gemiddelde van al die klimaatmodellen. Wat heeft het gemiddelde van 100 hypotheses voor meerwaarde boven elk van die modellen? Het blijkt een onzingegeven. Is de statistische methode hier wel van toepassing? Nee dus.
Can we apply this sort of thoughtful reasoning the spaghetti snarl of GCMs and their highly divergent results? You bet we can! First of all, we could stop pretending that “ensemble” mean and variance have any meaning whatsoever by not computing them. Why compute a number that has no meaning? Second, we could take the actual climate record from some “epoch starting point” — one that does not matter in the long run, and we’ll have to continue the comparison for the long run because in any short run from any starting point noise of a variety of sorts will obscure systematic errors — and we can just compare reality to the models. We can then sort out the models by putting (say) all but the top five or so into a “failed” bin and stop including them in any sort of analysis or policy decisioning whatsoever unless or until they start to actually agree with reality.
Vooralsnog presteerden de modellen zo slecht in hindcasting, dat er geen reden is ze aan te merken als leidend voor mondiaal beleid. Hier past het continue uit de pas lopen van de meetgegevens naadloos bij in het licht van het gestegen CO2-gehalte in de atmosfeer.
Let me repeat this.It has no meaning!It is indefensible within the theory and practice of statistical analysis. You might as well use a ouija board as the basis of claims about the future climate history as the ensemble average of different computational physical models that do not differ by truly random variations and are subject to all sorts of omitted variable, selected variable, implementation, and initialization bias. The board might give you the right answer, might not, but good luck justifying the answer it gives on some sort of rational basis.
Laten we tot slot kijken naar die klimaatmodellen zelf.
Wat opvalt is de rol van bewolking, een natuurlijk effect dat de modellen uitsluiten, het effect ervan op de ‘voorspellende’ uitkomsten van de klimaatmodellen en de groeiende onzekerheid (error).
The average energy impact of clouds on Earth climate is worth about -27.6 W/m2. That means ±10.1% error produces a ±2.8 W/m2 uncertainty in GCM climate projections. This uncertainty equals about ±100 % of the current excess forcing produced by all the human-generated greenhouse gasses presently in the atmosphere. Taking it into account will reflect a true, but incomplete, estimate of the physical reliability of a GCM temperature trend.
So, what happens when this ±2.8 W/m2 is propagated through the SRES temperature trends offered by the IPCC in Figure SPM-5 (Figure 1)? When calculating a year-by-year temperature projection, each new temperature plus its physical uncertainty gets fed into the calculation of the next year’s temperature plus its physical uncertainty. This sort of uncertainty accumulates each year because every predicted temperature includes its entire ± (physical uncertainty) range (SI Section 4).
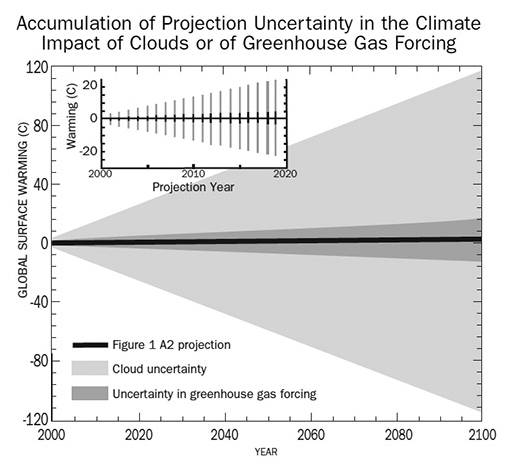 Het resultaat leidt tot exploderen van die modellen. Bewolking is zeker niet de enige natuurlijke factor. Daar zijn ook de zon, oceanische stromingen et cetera, die het IPCC buiten zijn modellen houdt. De modellen van het IPCC zijn om dus evidente redenen uiterst discutabel. Hoe het er in statistisch-rekenkundig detail uit ziet kunt u in deze lezing zien. De cijfers verschillen iets, maar de boodschap is idem. De conclusie is dat het IPCC de wetenschappelijke methode negeert, hierdoor onjuiste informatie verstrekt en zich als een onbetrouwbare organisatie ontpopt met virtually likely sociaal-democratische doelstellingen.
Het resultaat leidt tot exploderen van die modellen. Bewolking is zeker niet de enige natuurlijke factor. Daar zijn ook de zon, oceanische stromingen et cetera, die het IPCC buiten zijn modellen houdt. De modellen van het IPCC zijn om dus evidente redenen uiterst discutabel. Hoe het er in statistisch-rekenkundig detail uit ziet kunt u in deze lezing zien. De cijfers verschillen iets, maar de boodschap is idem. De conclusie is dat het IPCC de wetenschappelijke methode negeert, hierdoor onjuiste informatie verstrekt en zich als een onbetrouwbare organisatie ontpopt met virtually likely sociaal-democratische doelstellingen.